Так как я часто имею дело с большим количеством данных, у меня время от времени возникает необходимость генерировать массивы значений для проверки моделей в Excel. К примеру, если я хочу увидеть распределение веса продукта с определенным стандартным отклонением, потребуются некоторые усилия, чтобы привести результат работы формулы СЛУЧМЕЖДУ() в нормальный вид. Дело в том, что формула СЛУЧМЕЖДУ() выдает числа с единым распределением, т.е. любое число с одинаковой долей вероятности может оказаться как у нижней, так и у верхней границы запрашиваемого диапазона. Такое положение дел не соответствует действительности, так как вероятность возникновения продукта уменьшается по мере отклонения от целевого значения. Т.е. если я произвожу продукт весом 100 грамм, вероятность, что я произведу 97-ми или 103-граммовый продукт меньше, чем 100 грамм. Вес большей части произведенной продукции будет сосредоточен рядом с целевым значением. Такое распределение называется нормальным. Если построить график, где по оси Y отложить вес продукта, а по оси X – количество произведенного продукта, график будет иметь колоколообразный вид, где наивысшая точка будет соответствовать целевому значению.
Таким образом, чтобы привести массив, выданный формулой СЛУЧМЕЖДУ(), в нормальный вид, мне приходилось ручками исправлять пограничные значения на близкие к целевым. Такое положение дел меня, естественно, не устраивало, поэтому, покопавшись в интернете, открыл интересный способ создания массива данных с нормальным распределением. В сегодняшней статье описан способ генерации массива и построения графика с нормальным распределением.
Характеристики нормального распределения
Непрерывная случайная переменная, которая подчиняется нормальному распределению вероятностей, обладает некоторыми особыми свойствами. Предположим, что вся производимая продукция подчиняется нормальному распределению со средним значением 100 грамм и стандартным отклонением 3 грамма. Распределение вероятностей для такой случайной переменной представлено на рисунке.
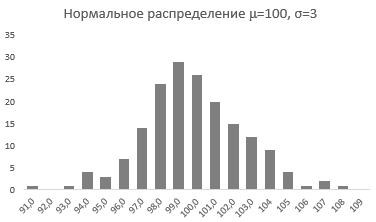
Из этого рисунка мы можем сделать следующие наблюдения относительно нормального распределения — оно имеет форму колокола и симметрично относительно среднего значения.
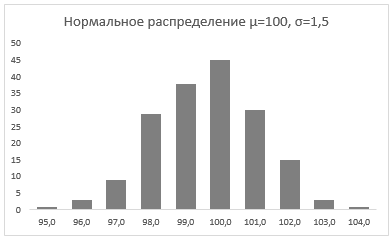
Стандартное отклонение имеет немаловажную роль в форме изгиба. Если посмотреть на предыдущий рисунок, то можно заметить, что практически все измерения веса продукта попадают в интервал от 95 до 105 граммов. Давайте рассмотрим следующий рисунок, на котором представлено нормальное распределение с той же средней – 100 грамм, но со стандартным отклонением всего 1,5 грамма
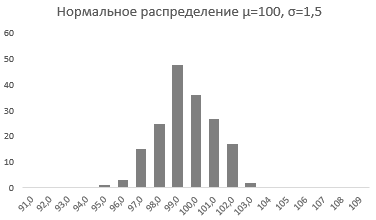
Здесь вы видите, что измерения значительно плотней прилегают к среднему значению. Почти все производимые продукты попадают в интервал от 97 до 102 грамм.
Небольшое значение стандартного отклонения выражается в более «тощей и высокой кривой, плотно прижимающейся к среднему значению. Чем больше стандартное, тем «толще», ниже и растянутее получается кривая.
Создание массива с нормальным распределением
Итак, чтобы сгенерировать массив данных с нормальным распределением, нам понадобится функция НОРМ.ОБР() – это обратная функция от НОРМ.РАСП(), которая возвращает нормально распределенную переменную для заданной вероятности для определенного среднего значения и стандартного отклонения. Синтаксис формулы выглядит следующим образом:
=НОРМ.ОБР(вероятность; среднее_значение; стандартное_отклонение)
Другими словами, я прошу Excel посчитать, какая переменная будет находится в вероятностном промежутке от 0 до 1. И так как вероятность возникновения продукта с весом в 100 грамм максимальная и будет уменьшаться по мере отдаления от этого значения, то формула будет выдавать значения близких к 100 чаще, чем остальных.
Давайте попробуем разобрать на примере. Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5.
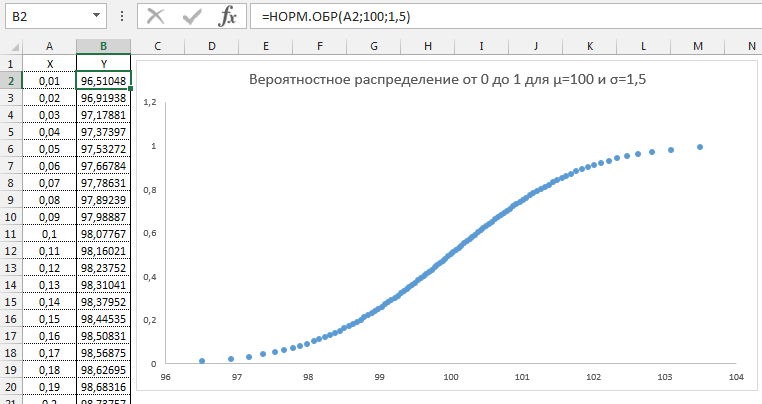
Как видим из графика точки максимально сконцентрированы у переменной 100 и вероятности 0,5.
Этот фокус мы используем для генерирования случайного массива данных с нормальным распределением. Формула будет выглядеть следующим образом:
=НОРМ.ОБР(СЛЧИС(); среднее_значение; стандартное_отклонение)
Создадим массив данных для нашего примера со средним значением 100 грамм и стандартным отклонением 1,5 грамма и протянем нашу формулу вниз.
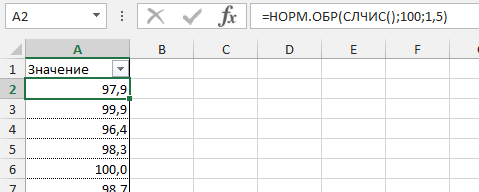
Теперь, когда массив данных готов, мы можем выстроить график с нормальным распределением.
Построение графика нормального распределения
Прежде всего необходимо разбить наш массив на периоды. Для этого определяем минимальное и максимальное значение, размер каждого периода или шаг, с которым будет увеличиваться период.
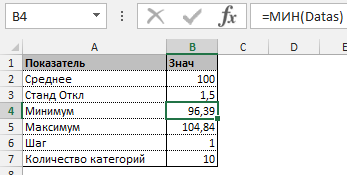
Далее строим таблицу с категориями. Нижняя граница (B11) равняется округленному вниз ближайшему кратному числу. Остальные категории увеличиваются на значение шага. Формула в ячейке B12 и последующих будет выглядеть:
=ЕСЛИ(A12;B11+$B$6; «»)
В столбце X будет производится подсчет количества переменных в заданном промежутке. Для этого воспользуемся формулой ЧАСТОТА(), которая имеет два аргумента: массив данных и массив интервалов. Выглядеть формула будет следующим образом =ЧАСТОТА(Data!A1:A175;B11:B20). Также стоит отметить, что в таком варианте данная функция будет работать как формула массива, поэтому по окончании ввода необходимо нажать сочетание клавиш Ctrl+Shift+Enter.
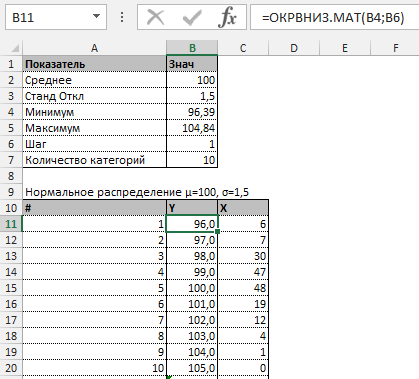
Таким образом у нас получилась таблица с данными, с помощью которой мы сможем построить диаграмму с нормальным распределением. Воспользуемся диаграммой вида Гистограмма с группировкой, где по оси значений будет отложено количество переменных в данном промежутке, а по оси категорий – периоды.
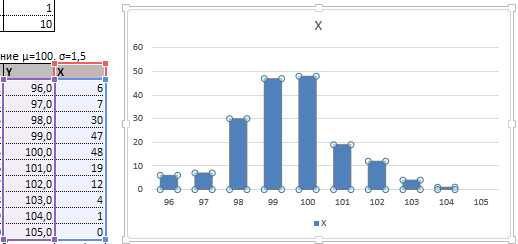
Осталось отформатировать диаграмму и наш график с нормальным распределением готов.
Итак, мы познакомились с вами с нормальным распределением, узнали, что Excel позволяет генерировать массив данных с помощью формулы НОРМ.ОБР() для определенного среднего значения и стандартного отклонения и научились приводить данный массив в графический вид.
Для лучшего понимания, вы можете скачать файл с примером построения нормального распределения.
Ренат, добрый день.
Все несколько проще:
Данные->Анализ данных->Генерация случайных чисел (Распределение=Нормальное)
+
Данные->Анализ данных->Гистограмма->Галка на «вывод графика» («Карманы» можно даже не задавать)
Круто, спасибо за комментарий
Невозможно воспользоваться вашим советом. вы объясняете кусками. У меня есть большой массив данных. не рандомизированных, не построенных, просто набор цифр. мне нужно построить по ним нормальное распределение. Точнее построить распределение, потом глянуть на графике будет ли оно нормальным. Через список по порядку Ексель данные выстраивать не стал, вероятность каждой цифры в массиве не считает, а все построения идут от этой вероятности… Короче, объяснения для программистов-математиков для них же, а не для практиков((((( не нужны такие
Люба, жаль, что статья вам не помогла. Попробуйте воспользоваться советом AnanevHA — первый комментарий к этой статье
Сейчас время дипломов, тысячи студентов-гуманитариев вспоминают непонятную статистику, и самое первое, что нужно сделать для описания результатов исследования — понять, нормальное распределение в твоей выборке, или нет. Во всех учебниках это изображается диаграммой или графиком, но как из сотни сырых значений получить эту картинку-колокол? Эта статья выдается первой по запросу, но вот честно, без базовых знаний статистики хрен что поймешь. Я 5 дней разбирался, и с этой статьей в том числе. Так ничего и не понял, зачем все это написано)
Я, как и предыдущий комментатор «Люба», ищу основы, и вот как я в итоге выкрутился из этой ситуации, вдруг кому поможет:
1. Все сырые данные выстроить по возрастанию в один столбец.
2. Вкладка «Данные» -> «Анализ данных» (если нету, этот пакет можно загрузить, погуглите, как)
3. Выбираем «Описательная статистика», во входные данные — наш столбец с данными, выходные — любая ненужная ячейка или новый лист.
4. Нам выводятся все необходимые базовые характеристики выборки. Находим среднее значение, копируем и заполняем этим числом весь второй столбец, напротив наших данных.
5. В третий столбец также копипастим стандартное отклонение.
6. В четвертом столбце наводим на первую, пока еще пустую, ячейку и вызываем мастер функций (fx)
7. Ищем там НОРМРАСП.
8. В поле Х вставляем ячейку с данными из первого столбца и первой строки, в поле «среднее» соответственно среднее (из второго столбца), в поле «станд. отклонение» — стандартное отклонение из третьего столбца, в поле «интегральная» вводим 0 (ложь).
9. Для первой строки готово. Теперь растягиваем автозаполнением эту ячейку вниз и данные для нормального распределения у нас есть!
10. Выделяем их и тыкаем «Вставка» -> «Диаграмма».
Мне кажется, это не то же самое, что описано в этой статье, и может быть, я вообще сделал что-то не то. Но график получился как надо, для описания исследования сойдет:-)
Не знаю как на счет кусков — мне всё было ясно и понятно. На работе столкнулся с проблемой и с помощью этой статьи благополучно решил её! Большое спасибо, Ренат!
Стоило скачать файл, нажать кнопку «Разрешить редактирование», как тут же возникла ошибка в столбцах В и С и стало ничего не понять… Просьба перезалить упакованный файл, чтобы файл автоматом проверялся и ничего не слетало. Формулы массива не слетели, но что не так — не пойму.
Столько времени потеряно на разборы, но так ничего и не вышло. Жаль.
Здравствуйте. Спасибо за статью. От себя добавлю важный момент, как пользоваться функцией Частота. Сначала нужно выделить диапозон (В примере выше C11:C20), только потом ввести формулу =ЧАСТОТА(Data!A1:A175;B11:B20) в строку ввода формулы, а потом нажать Ctrl+Shift+Enter.
А не подскажите каким распределением пользоваться в случае когда допустим среднее 0,07, а отклонение равно 2 (Это продажи). То есть отрицательной области быть не может, а при нормальном распределении она получается. Я так понимаю тут другая функция.
Полезная статья, в частности, для изучения нормального распределения.
Для этой цели был создан официальный сайт , на котором и осуществляется продажа Unitox. Нажмите кнопку , размещенную ниже, и вы попадете на него. какое количество средства вы хотите приобрести; фамилию, имя и отчество, человека, который будет получать посылку на почте; адрес доставки. Оплачивать покупку или вносить предоплату не нужно: расчет за приобретенное средство будет осуществлен с момент получения посылки в почтовом отделении или у курьера. https://otzyvy-vrachej.com/realnye-otzyvy-o-rendez-vous-bystryy-i-silnyy-zhenskiy-vozbuditel.php Лапачо оказывает обезболивающее действие. Его используют при инфекционных и грибковых заболеваниях. Дынное дерево повышает эластичность кожи, заживляет раны. Алоэ обладает мощным заживляющим свойством. Уснея хорошо рубцует и заживляет раны, избавляет от шрамов. Бобровой струя укрепляет защитные функции. Марула благодаря высокому содержанию витамина С рекомендуется при грибковых поражениях. Обладает антисептическим свойством. Прополис обладает дермопластическим, обеззараживающим, иммуномодулирующим свойствами. Масло гвоздики — антисептик и успокаивающее средство. Кроме того Мицинорм содержит вытяжки крапивы, зверобоя, ромашки, лопуха, клевера, одуванчика, кордицепса, корицы, нима, мастики, дуба, корицы, лукума, магония, а также зерна винограда, семена амаранта, лимонную осину.
Иди нахуй со своим спамом. Тут форум математиков.
Здравствуйте. Не знаю уместен ли будет вопрос, но у меня очень мало времени для решения одной задачи, являющейся частью большого исследования. Можно ли найти количества материала, распределенного по фракциям (размеру частиц), если известен вес общей пробы. Т.е. на ситах просеивают агломерат. Можно ли узнать вес фракций 5-10, 10-15, 15-20, 20-25, 25-30, 30-35, 35-40 мм (всего 7 интервалов), если общий вес пробы составляет 15 кг? Естественно, в предположении, что агломерат распределяется по фракциям в соответствии с нормальным законом распределения. В общем-то не важно сколько интервалов и какие они имеют значения, но в принципе можно ли узнать в Excel распределение по нормальному закону n-го количества чего-то в m группах?
Не нужен Excel. Все элементарно делается в SPSS. В том числе проверка нормальности распределения делается загрузкой данных и потом в пару кликов. В частности проверка нормальности — путем проведения теста Колмогорова-Смирнова. Причем в в SPSS все предусмотрено. Excel — это программа широкого профиля и не заточена под статистические исследования, а SPSS — это узкоспециализированная программа.
А можно то же самое расписать полностью? если не Ексель, то все остальные проги платные.. Очень надо проверить данные на нормальность! Ничего не нашла(
у вас написано «Выстроим график распределения вероятностей от 0 до 1 с шагом 0,01 для среднего значения равным 100 и стандартным отклонением 1,5» но функция выдает число, вы задали график.. как?